Home Credit Default Risk Kaggle Competition
We’ll look at a pretty primitive problem, estimating credit default risk of a consumer on a loan. This is from the Kaggle competition here: https://www.kaggle.com/c/home-credit-default-risk. More interesting is some of the exploratory analysis we can do on the data to look at the relationship between income, occuptation and credit amounts.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
#payment_df = pd.read_csv(r"D:\Downloads\home_credit_data\installments_payments.csv") # repayment history one row for each payment/missed payment
#balance_df = pd.read_csv(r"D:\Downloads\home_credit_data\bureau_balance.csv") # monthly balances of previous credits
test_df = pd.read_csv(r"D:\Downloads\home_credit_data\application_test.csv")
train_df = pd.read_csv(r"D:\Downloads\home_credit_data\application_train.csv") # one row = one loan
#bureau_df = pd.read_csv(r"D:\Downloads\home_credit_data\bureau.csv") # clients previous credits/loadns
#pos_cash_df = pd.read_csv(r"D:\Downloads\home_credit_data\POS_CASH_balance.csv") # monthly balance of previous pos/cash loans
#creditcard_df = pd.read_csv(r"D:\Downloads\home_credit_data\credit_card_balance.csv") # monthly snapshots of previous credit cards
prevapp_df = pd.read_csv(r"D:\Downloads\home_credit_data\previous_application.csv") # all previous applications
Training Data
Let’s start with a high level view of the training data. Our goal is to predict the TARGET variable, where TARGET is described as 1 - client has payment difficulties and 0 - all other cases. Effectively, we want to predict whether a client will have difficulties repaying their loan based on the features we’ve been provided with.
Given the breadth of extra data provided, such as credit card histories, previous loan applications across all agencies and monthly snapshots of point-of-sale/cash loans, there’s a lot of scope for expanding the analysis. LET’S START SIMPLE!
train_df.info(max_cols = 200)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MB
train_df.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | AMT_GOODS_PRICE | NAME_TYPE_SUITE | NAME_INCOME_TYPE | NAME_EDUCATION_TYPE | NAME_FAMILY_STATUS | NAME_HOUSING_TYPE | REGION_POPULATION_RELATIVE | DAYS_BIRTH | DAYS_EMPLOYED | DAYS_REGISTRATION | DAYS_ID_PUBLISH | OWN_CAR_AGE | FLAG_MOBIL | FLAG_EMP_PHONE | FLAG_WORK_PHONE | FLAG_CONT_MOBILE | FLAG_PHONE | FLAG_EMAIL | OCCUPATION_TYPE | CNT_FAM_MEMBERS | REGION_RATING_CLIENT | REGION_RATING_CLIENT_W_CITY | WEEKDAY_APPR_PROCESS_START | HOUR_APPR_PROCESS_START | REG_REGION_NOT_LIVE_REGION | REG_REGION_NOT_WORK_REGION | LIVE_REGION_NOT_WORK_REGION | REG_CITY_NOT_LIVE_CITY | REG_CITY_NOT_WORK_CITY | LIVE_CITY_NOT_WORK_CITY | ORGANIZATION_TYPE | EXT_SOURCE_1 | EXT_SOURCE_2 | EXT_SOURCE_3 | APARTMENTS_AVG | BASEMENTAREA_AVG | YEARS_BEGINEXPLUATATION_AVG | YEARS_BUILD_AVG | COMMONAREA_AVG | ELEVATORS_AVG | ENTRANCES_AVG | FLOORSMAX_AVG | FLOORSMIN_AVG | LANDAREA_AVG | LIVINGAPARTMENTS_AVG | LIVINGAREA_AVG | NONLIVINGAPARTMENTS_AVG | NONLIVINGAREA_AVG | APARTMENTS_MODE | BASEMENTAREA_MODE | YEARS_BEGINEXPLUATATION_MODE | YEARS_BUILD_MODE | COMMONAREA_MODE | ELEVATORS_MODE | ENTRANCES_MODE | FLOORSMAX_MODE | FLOORSMIN_MODE | LANDAREA_MODE | LIVINGAPARTMENTS_MODE | LIVINGAREA_MODE | NONLIVINGAPARTMENTS_MODE | NONLIVINGAREA_MODE | APARTMENTS_MEDI | BASEMENTAREA_MEDI | YEARS_BEGINEXPLUATATION_MEDI | YEARS_BUILD_MEDI | COMMONAREA_MEDI | ELEVATORS_MEDI | ENTRANCES_MEDI | FLOORSMAX_MEDI | FLOORSMIN_MEDI | LANDAREA_MEDI | LIVINGAPARTMENTS_MEDI | LIVINGAREA_MEDI | NONLIVINGAPARTMENTS_MEDI | NONLIVINGAREA_MEDI | FONDKAPREMONT_MODE | HOUSETYPE_MODE | TOTALAREA_MODE | WALLSMATERIAL_MODE | EMERGENCYSTATE_MODE | OBS_30_CNT_SOCIAL_CIRCLE | DEF_30_CNT_SOCIAL_CIRCLE | OBS_60_CNT_SOCIAL_CIRCLE | DEF_60_CNT_SOCIAL_CIRCLE | DAYS_LAST_PHONE_CHANGE | FLAG_DOCUMENT_2 | FLAG_DOCUMENT_3 | FLAG_DOCUMENT_4 | FLAG_DOCUMENT_5 | FLAG_DOCUMENT_6 | FLAG_DOCUMENT_7 | FLAG_DOCUMENT_8 | FLAG_DOCUMENT_9 | FLAG_DOCUMENT_10 | FLAG_DOCUMENT_11 | FLAG_DOCUMENT_12 | FLAG_DOCUMENT_13 | FLAG_DOCUMENT_14 | FLAG_DOCUMENT_15 | FLAG_DOCUMENT_16 | FLAG_DOCUMENT_17 | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | 351000.0 | Unaccompanied | Working | Secondary / secondary special | Single / not married | House / apartment | 0.018801 | -9461 | -637 | -3648.0 | -2120 | NaN | 1 | 1 | 0 | 1 | 1 | 0 | Laborers | 1.0 | 2 | 2 | WEDNESDAY | 10 | 0 | 0 | 0 | 0 | 0 | 0 | Business Entity Type 3 | 0.083037 | 0.262949 | 0.139376 | 0.0247 | 0.0369 | 0.9722 | 0.6192 | 0.0143 | 0.00 | 0.0690 | 0.0833 | 0.1250 | 0.0369 | 0.0202 | 0.0190 | 0.0000 | 0.0000 | 0.0252 | 0.0383 | 0.9722 | 0.6341 | 0.0144 | 0.0000 | 0.0690 | 0.0833 | 0.1250 | 0.0377 | 0.022 | 0.0198 | 0.0 | 0.0 | 0.0250 | 0.0369 | 0.9722 | 0.6243 | 0.0144 | 0.00 | 0.0690 | 0.0833 | 0.1250 | 0.0375 | 0.0205 | 0.0193 | 0.0000 | 0.00 | reg oper account | block of flats | 0.0149 | Stone, brick | No | 2.0 | 2.0 | 2.0 | 2.0 | -1134.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 100003 | 0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | 1129500.0 | Family | State servant | Higher education | Married | House / apartment | 0.003541 | -16765 | -1188 | -1186.0 | -291 | NaN | 1 | 1 | 0 | 1 | 1 | 0 | Core staff | 2.0 | 1 | 1 | MONDAY | 11 | 0 | 0 | 0 | 0 | 0 | 0 | School | 0.311267 | 0.622246 | NaN | 0.0959 | 0.0529 | 0.9851 | 0.7960 | 0.0605 | 0.08 | 0.0345 | 0.2917 | 0.3333 | 0.0130 | 0.0773 | 0.0549 | 0.0039 | 0.0098 | 0.0924 | 0.0538 | 0.9851 | 0.8040 | 0.0497 | 0.0806 | 0.0345 | 0.2917 | 0.3333 | 0.0128 | 0.079 | 0.0554 | 0.0 | 0.0 | 0.0968 | 0.0529 | 0.9851 | 0.7987 | 0.0608 | 0.08 | 0.0345 | 0.2917 | 0.3333 | 0.0132 | 0.0787 | 0.0558 | 0.0039 | 0.01 | reg oper account | block of flats | 0.0714 | Block | No | 1.0 | 0.0 | 1.0 | 0.0 | -828.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 100004 | 0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | 135000.0 | Unaccompanied | Working | Secondary / secondary special | Single / not married | House / apartment | 0.010032 | -19046 | -225 | -4260.0 | -2531 | 26.0 | 1 | 1 | 1 | 1 | 1 | 0 | Laborers | 1.0 | 2 | 2 | MONDAY | 9 | 0 | 0 | 0 | 0 | 0 | 0 | Government | NaN | 0.555912 | 0.729567 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 0.0 | 0.0 | 0.0 | -815.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 100006 | 0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | 297000.0 | Unaccompanied | Working | Secondary / secondary special | Civil marriage | House / apartment | 0.008019 | -19005 | -3039 | -9833.0 | -2437 | NaN | 1 | 1 | 0 | 1 | 0 | 0 | Laborers | 2.0 | 2 | 2 | WEDNESDAY | 17 | 0 | 0 | 0 | 0 | 0 | 0 | Business Entity Type 3 | NaN | 0.650442 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2.0 | 0.0 | 2.0 | 0.0 | -617.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | 513000.0 | Unaccompanied | Working | Secondary / secondary special | Single / not married | House / apartment | 0.028663 | -19932 | -3038 | -4311.0 | -3458 | NaN | 1 | 1 | 0 | 1 | 0 | 0 | Core staff | 1.0 | 2 | 2 | THURSDAY | 11 | 0 | 0 | 0 | 0 | 1 | 1 | Religion | NaN | 0.322738 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 0.0 | 0.0 | 0.0 | -1106.0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
Loans and Income
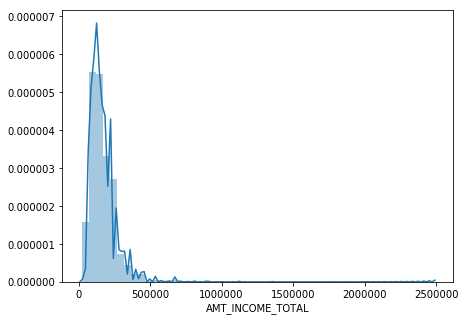
We can see that the AMT_INCOME_TOTAL is heavily skewed by the high income earners, where the highest income earning is $117,000,00 and the lowest is $25,650. Once removing the larger outliers we can get a better picture of the distribution.
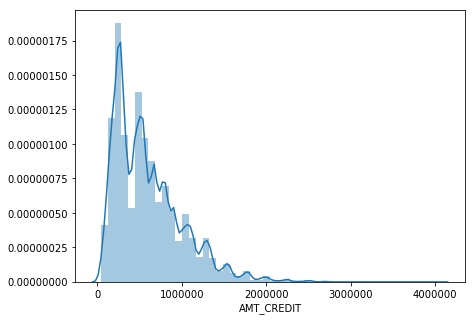
The AMT_CREDIT seems to be slightly bi-modal, which is likely a function of the property markets that the loans are coming from.
train_df['AMT_INCOME_TOTAL'].max()
117000000.0
train_df['AMT_INCOME_TOTAL'].min()
25650.0
plt.figure(figsize=(7,5))
sns.distplot(train_df['AMT_INCOME_TOTAL'].dropna())
plt.show()
plt.figure(figsize=(7,5))
sns.distplot(train_df.loc[train_df['AMT_INCOME_TOTAL'] < 0.25e7, 'AMT_INCOME_TOTAL'].dropna())
plt.show()
plt.figure(figsize=(7,5))
sns.distplot(train_df['AMT_CREDIT'].dropna())
plt.show()
plt.figure(figsize=(7,5))
sns.distplot(train_df['AMT_ANNUITY'].dropna())
plt.show()
plt.figure(figsize=(7,5))
sns.distplot(train_df['AMT_GOODS_PRICE'].dropna())
plt.show()

Occupation vs Income/Credit
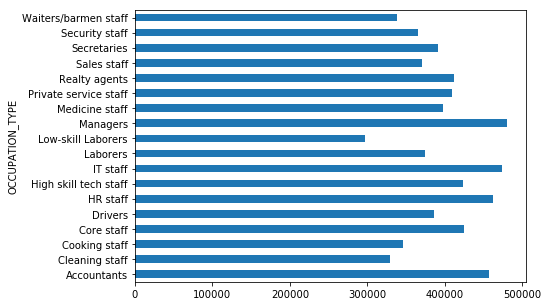
Interestingly, we see that laborers are by far the biggest users of loans, and also have the greatest variance in incomes! Not unexpected, but the average loan amounts seem fairly consistent.
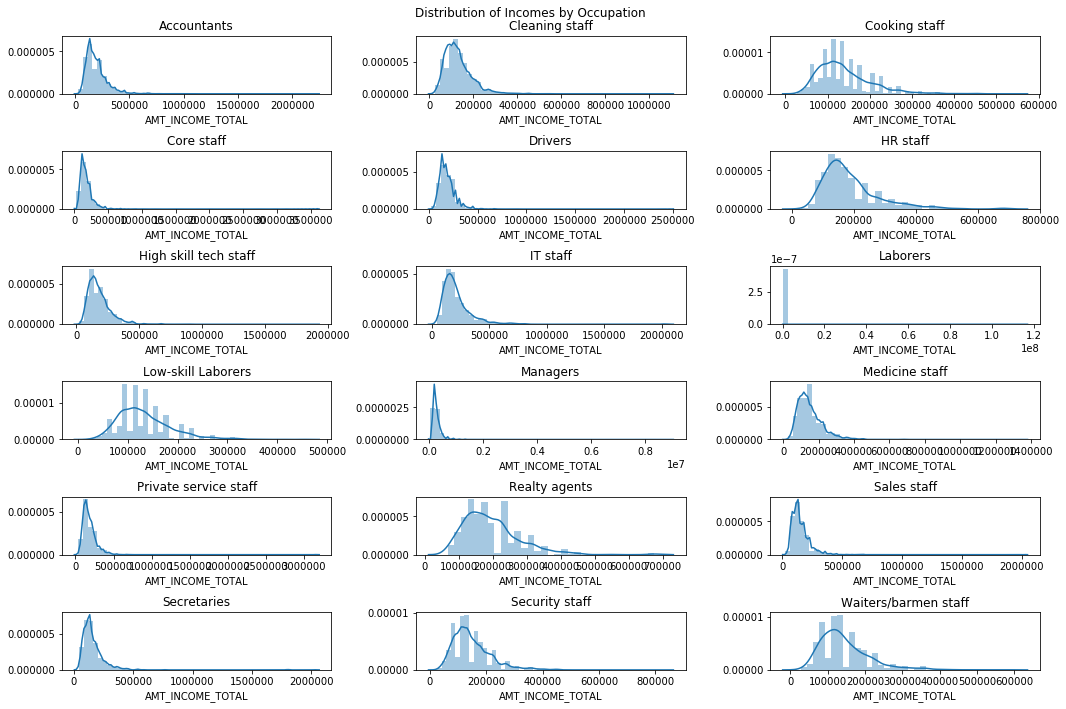
More interestingly, we can look at the distribution of income across different job types! Notice that there are roughly two “types” of distributions:
- Tight with long tails (accountants, cleaning staff, managers)
- Wide with not much of a tail (realty agents, low skill labor)
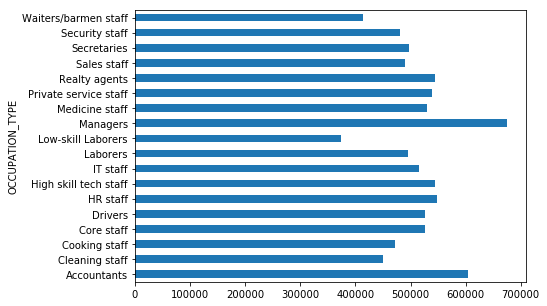
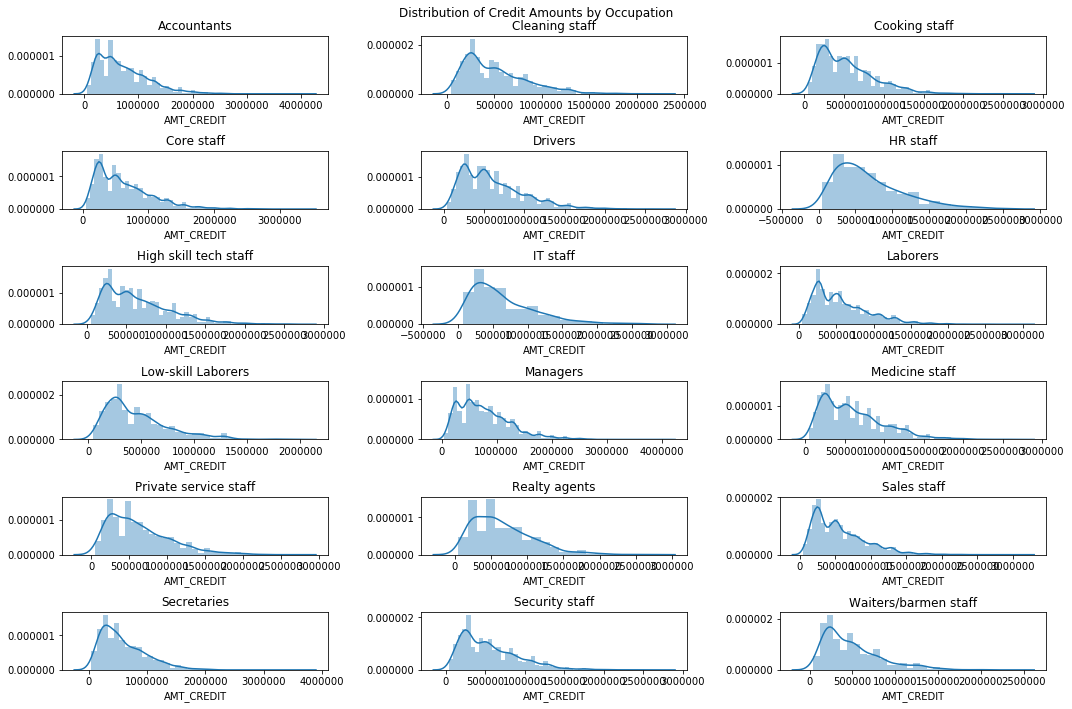
We also note that the distribution in credit amounts are roughly consistent across each occupation grouping
train_df.groupby(['OCCUPATION_TYPE'])['OCCUPATION_TYPE'].count().sort_values(ascending=False).plot(kind='barh', figsize=(7,5))
plt.show()
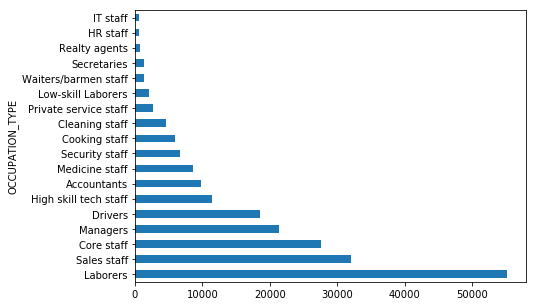
train_df.groupby(['OCCUPATION_TYPE'])['AMT_INCOME_TOTAL'].median().plot(kind='barh', figsize=(7,5))
plt.show()
train_df.groupby(['OCCUPATION_TYPE'])['AMT_INCOME_TOTAL'].std().plot(kind='barh', figsize=(7,5))
plt.show()
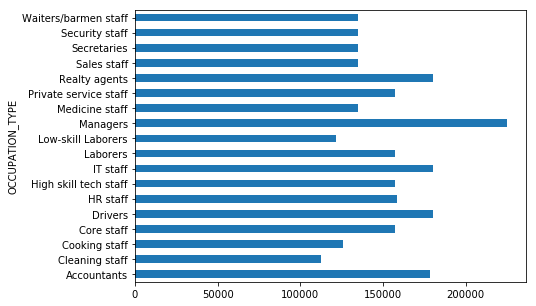
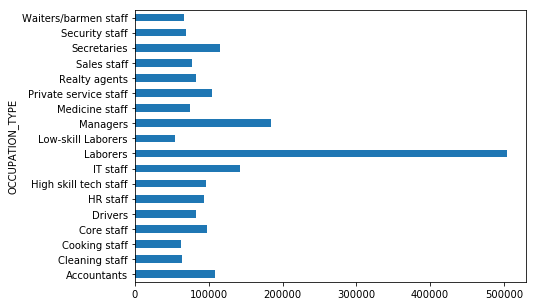
train_df.groupby(['OCCUPATION_TYPE'])['AMT_CREDIT'].median().plot(kind='barh', figsize=(7,5))
plt.show()
train_df.groupby(['OCCUPATION_TYPE'])['AMT_CREDIT'].std().plot(kind='barh', figsize=(7,5))
plt.show()
fig, axes = plt.subplots(nrows=6, ncols=3, figsize=(15,10))
plt.suptitle('Distribution of Incomes by Occupation')
j = 0
for i in np.unique(train_df['OCCUPATION_TYPE'].dropna()):
sns.distplot(train_df.loc[train_df['OCCUPATION_TYPE']==i, 'AMT_INCOME_TOTAL'], ax=axes.flat[j])
axes.flat[j].set_title(i)
j += 1
plt.tight_layout()
plt.subplots_adjust(top=0.94)
plt.show()
fig, axes = plt.subplots(nrows=6, ncols=3, figsize=(15,10))
plt.suptitle('Distribution of Credit Amounts by Occupation')
j = 0
for i in np.unique(train_df['OCCUPATION_TYPE'].dropna()):
sns.distplot(train_df.loc[train_df['OCCUPATION_TYPE']==i, 'AMT_CREDIT'], ax=axes.flat[j])
axes.flat[j].set_title(i)
j += 1
plt.tight_layout()
plt.subplots_adjust(top=0.94)
plt.show()
Categorical Variables - Education, living situation…
train_df.groupby(['NAME_EDUCATION_TYPE'])['NAME_EDUCATION_TYPE'].count().sort_values(ascending=False).plot(kind='barh')
plt.show()
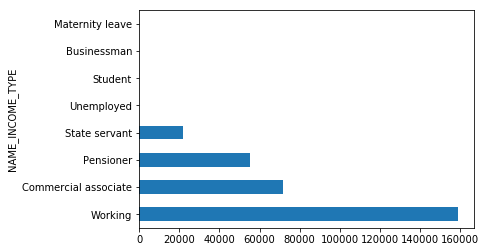
train_df.groupby(['NAME_INCOME_TYPE'])['NAME_INCOME_TYPE'].count().sort_values(ascending=False).plot(kind='barh')
plt.show()
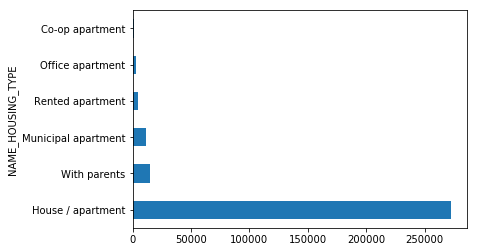
train_df.groupby(['NAME_HOUSING_TYPE'])['NAME_HOUSING_TYPE'].count().sort_values(ascending=False).plot(kind='barh')
plt.show()
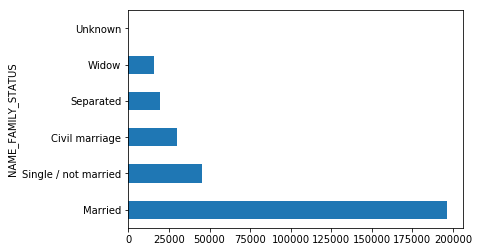
train_df.groupby(['NAME_FAMILY_STATUS'])['NAME_FAMILY_STATUS'].count().sort_values(ascending=False).plot(kind='barh')
plt.show()
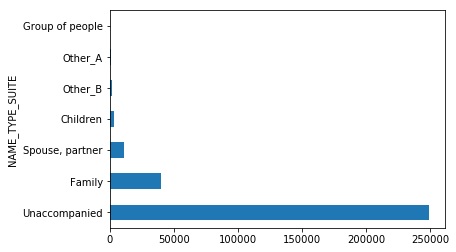
train_df.groupby(['NAME_TYPE_SUITE'])['NAME_TYPE_SUITE'].count().sort_values(ascending=False).plot(kind='barh')
plt.show()
sns.distplot(train_df['DAYS_BIRTH']/365)
plt.show()
sns.distplot(train_df['DAYS_EMPLOYED']/365)
plt.show()
sns.distplot(train_df['DAYS_REGISTRATION']/365)
plt.show()
sns.distplot(train_df['DAYS_ID_PUBLISH']/365)
plt.show()
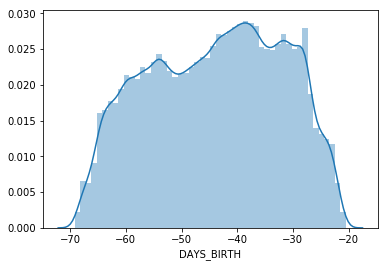
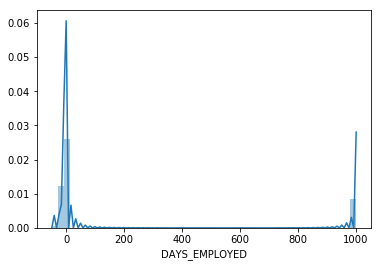
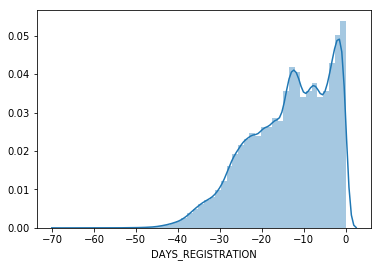
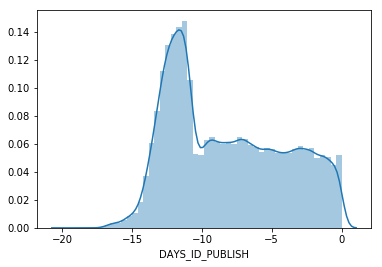
Correlation across dataset
I don’t particularly feel it advantageous to examine every aspect of this dataset. So we can cheat a bit and see if there are any interesting correlation patterns across the numeric datatypes
corrs = train_df.corr()
plt.figure(figsize=(20,20))
sns.heatmap(corrs)
plt.show()
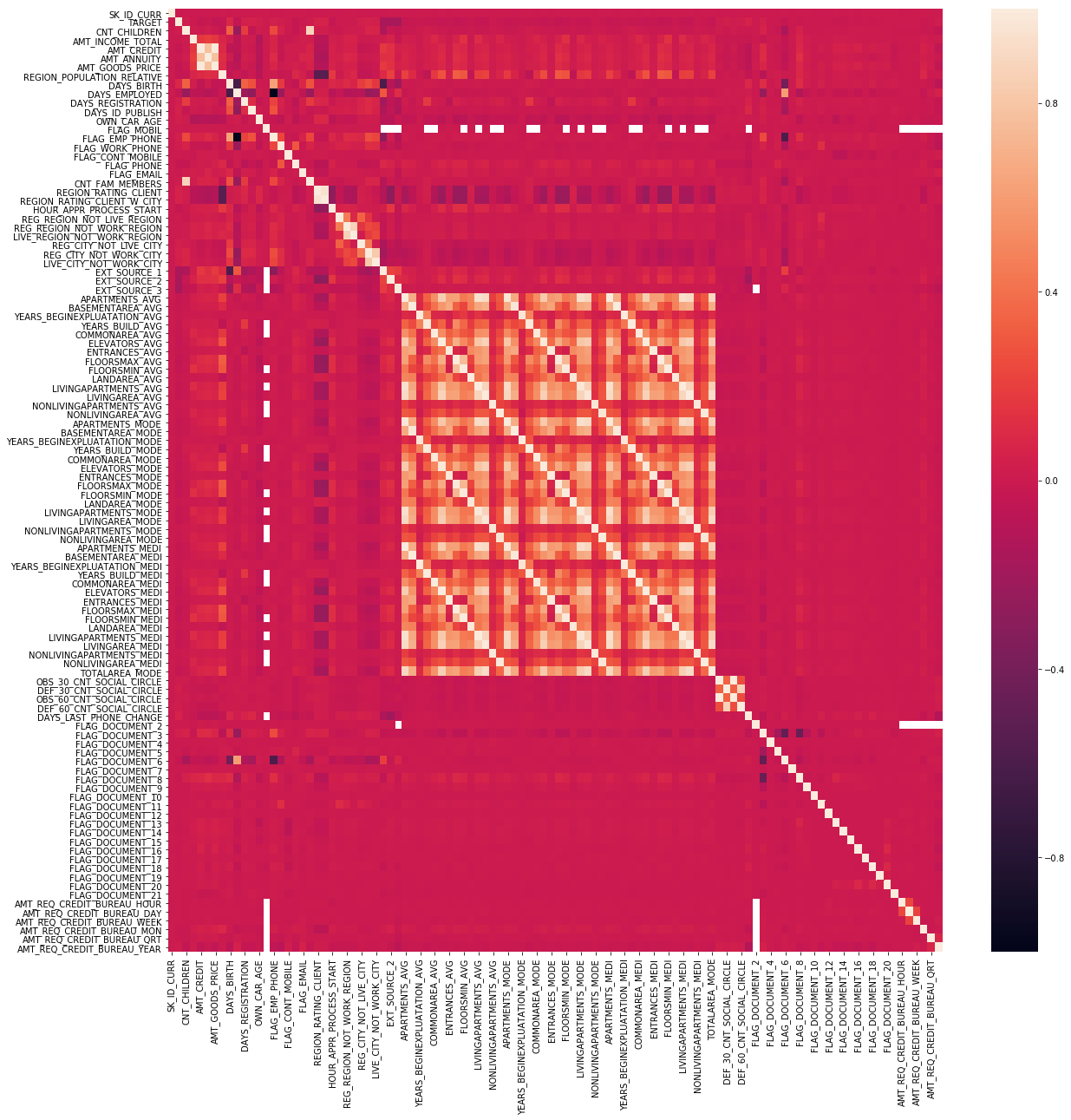
We can see a nice cluster of highly correlated features, mostly pertaining to aspects of the property (not unexpected!).
plt.figure(figsize=(20,20))
sns.clustermap(corrs.dropna())
plt.show()
<matplotlib.figure.Figure at 0x25fcc729cc0>

Prediction! What we care about!
First we’ll want to clean up some of the non-numeric data… and then just run some incredibly basic models to demonstrate how to produce a submission for the competition!
#Preprocessing
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#Algos
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
#Postprocessing
from sklearn.feature_selection import SelectFromModel
from sklearn.metrics import accuracy_score
from xgboost import plot_importance
cat_f = [x for x in train_df.columns if train_df[x].dtype == 'object']
for name in cat_f:
enc = preprocessing.LabelEncoder()
enc.fit(list(train_df[name].values.astype('str')) + list(test_df[name].values.astype('str')))
test_df[name] = enc.transform(test_df[name].values.astype('str'))
train_df[name] = enc.transform(train_df[name].values.astype('str'))
X_train = train_df.drop(['SK_ID_CURR', 'TARGET'], axis=1)
y_train = train_df['TARGET']
X_train.fillna(-1000, inplace=True) # hopefully ok...
# our test dataset doesn't have a target variable, so we'll have to test on the train df using holdout
x_train, x_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
#X_test = test_df.drop(['SK_ID_CURR', 'TARGET'], axis=1)
#y_test = test_df['TARGET']
clf = LogisticRegression()
clf.fit(x_train, y_train)
print("Logistic Regr. Score = ", clf.score(x_test, y_test))
C:\Users\Clint_PC\Anaconda3\lib\site-packages\sklearn\cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
Logistic Regr. Score = 0.9197274929678227
clf3 = XGBClassifier()
clf3.fit(x_train, y_train)
print("XGBoost Score = ", clf3.score(x_test, y_test))
XGBoost Score = 0.9199876428792091
C:\Users\Clint_PC\Anaconda3\lib\site-packages\sklearn\preprocessing\label.py:151: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
if diff:
clf4 = KNeighborsClassifier()
clf4.fit(x_train, y_train)
print("KNN Score = ", clf4.score(x_test, y_test))
KNN Score = 0.9136952668975498
clf5 = RandomForestClassifier()
clf5.fit(x_train, y_train)
print("Random Forest Score = ", clf5.score(x_test, y_test))
Random Forest Score = 0.9184755215192755
ax = plot_importance(clf3)
fig = ax.figure
fig.set_size_inches(15, 10)
plt.show()
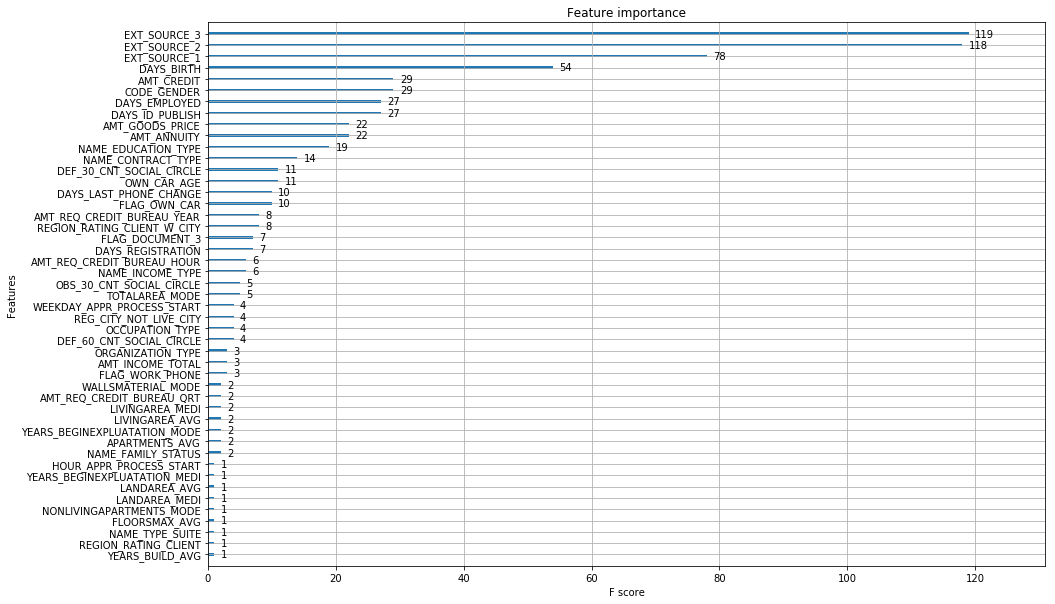
# select features using threshold
selection = SelectFromModel(clf3, threshold=0.05, prefit=True)
select_X_train = selection.transform(x_train)
# train model
selection_model = XGBClassifier()
selection_model.fit(select_X_train, y_train)
# eval model
X_test = test_df.fillna(-1000)
select_X_test = selection.transform(X_test.drop(['SK_ID_CURR'], axis=1))
y_pred = selection_model.predict(select_X_test)
C:\Users\Clint_PC\Anaconda3\lib\site-packages\sklearn\preprocessing\label.py:151: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
if diff:
y_pred = selection_model.predict_proba(select_X_test)
y_pred = pd.DataFrame(y_pred)
submission = pd.DataFrame()
submission['SK_ID_CURR'] = test_df['SK_ID_CURR']
submission['TARGET'] = y_pred.iloc[:, 1]
submission.to_csv('submission.csv', index=False)
submission.head()
| SK_ID_CURR | TARGET | |
|---|---|---|
| 0 | 100001 | 0.041684 |
| 1 | 100005 | 0.081148 |
| 2 | 100013 | 0.030166 |
| 3 | 100028 | 0.046527 |
| 4 | 100038 | 0.148846 |